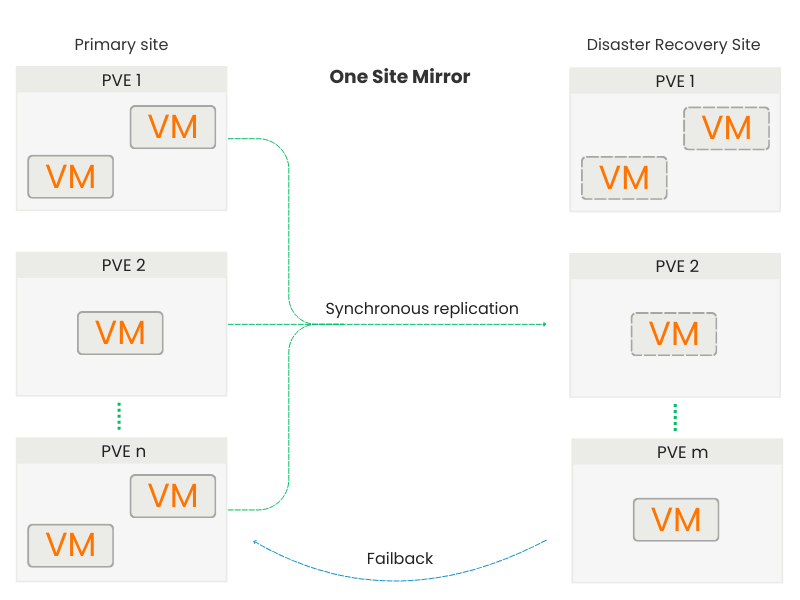
Use Case 1: One Site Mirror
Primary Site to Disaster Recovery Site
In this classic disaster recovery model, a single primary site performs continuous replication of its volumes to a secondary site dedicated to DR.
The DR Site maintains updated copies of the VMs, which remain in a standby state until eventual activation.
In the event of a fault or maintenance of the primary site, the DR Site is promoted and the VMs are started in operational mode..
Upon restoration of the Primary Site, the replication flow is reversed: updated data on the DR site is synchronized back to the main headquarters, allowing for an orderly return without loss of consistency.
The model is ideal for centralized infrastructures or those with a single production data center and a remote site dedicated to recovery.
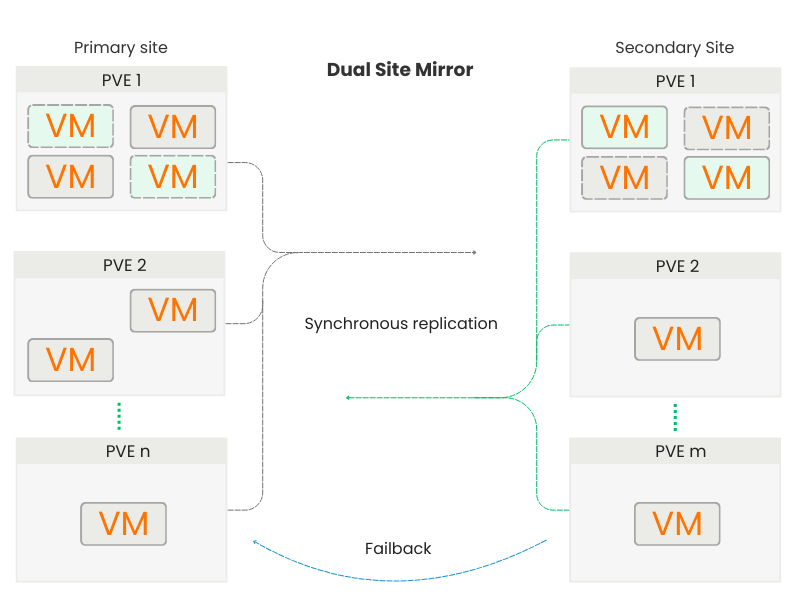
This model offers maximum resilience and load balancing in contexts with two equivalent data centers and high-performance connectivity, allowing companies to fully exploit both infrastructures for both production and business continuity.
Use Case 2: Dual Site Mirror
Bidirectional Replication Between Two Sites
In the Dual Site Mirror model, both locations operate as active sites and simultaneously as reciprocal Disaster Recovery sites. Each cluster performs continuous replication of its VMs to the other site, maintaining updated copies of the data in synchronous mode.
Under normal conditions, each site manages its own production workloads, while the replicated VMs remain in standby on the other cluster. In the event of a fault or unavailability of one of the two sites, the remote cluster assumes the primary role for the replicated VMs, ensuring operational continuity without significant interruptions.
Once the original site is restored, MSDR automatically reverses the replication flow, synchronizing the updated data and realigning the volumes to allow for an orderly return to the initial configuration.
Use case 3: Multi Site Mirror
Multiple Primary Sites to a single Disaster Recovery Site
In distributed environments with multiple operating sites or independent clusters, MSDR allows for the configuration of a shared DR site that receives replicas from multiple primary sites.
Each production cluster independently sends its own data to the DR cluster, maintaining a dedicated and isolated replication space for each source.
In the event of a failure at one of the locations, the DR site can promote only the volumes belonging to that location, starting the relative VMs without interfering with the replicas from the other locations that are still operational.
The selective promotion mechanism ensures that multiple environments can coexist within the same DR cluster, simplifying management and reducing overall infrastructure costs.
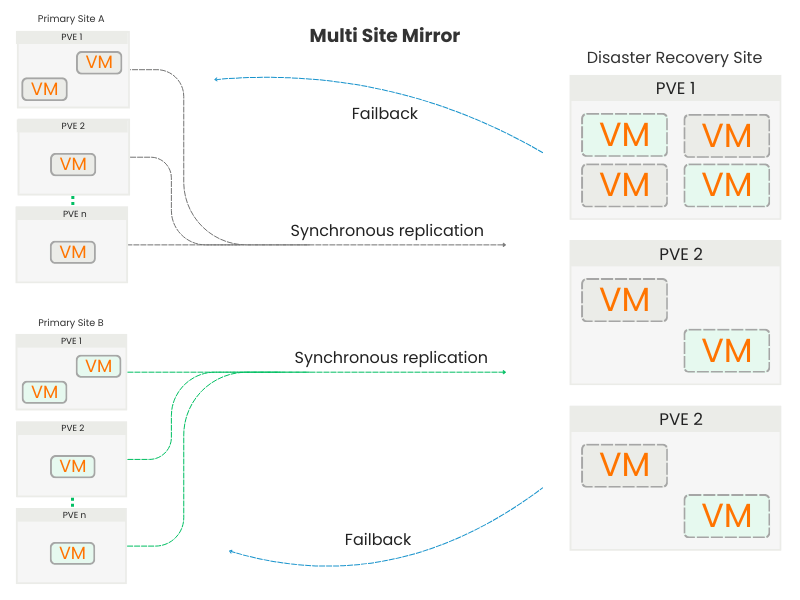
At the end of the emergency, the restored site resumes its function as primary, with reverse synchronization limited to its own volumes and with continuity of the other ongoing replicas.